#The Challenge: Managing AI Workloads Across GPU Clouds
Unlike the public cloud landscape dominated by AWS, GCP, and Azure, GPU marketplaces have historically lacked comprehensive infrastructure-as-code support. While adoption has been rising, teams building on these platforms often find themselves creating custom tooling to bridge the IaC gap that major providers have long since solved.
At Toffee, we run LLMs and image-generation models across multiple GPU clouds. We needed a way to provision and manage these workloads consistently, reliably, and at scale—without building and maintaining our own orchestration layer.
#Our Architecture with dstack
dstack solved that problem by providing a unified way to provision GPU resources and manage AI workloads via a straightforward, declarative API. Eventually, it became the foundation of our entire AI infrastructure.
We host most of our core, non-AI services on AWS, including our backend. The backend communicates with dstack Services through dstack Gateways, with each AI service backed by its own Gateway instance (essentially, an AWS EC2 host). To minimize attack surface and latency, all Gateways are accessible only within our AWS perimeter, exposed through Route53 Private Hosted Zone domains.
We provision GPU resources across RunPod and Vast.ai, giving us flexibility and cost optimization across multiple providers. dstack abstracts away the underlying differences between these clouds, so our services don't need to care where their GPUs are running.
Try it yourself: We've open-sourced a simplified version of this architecture in our demo repository, which shows how to deploy Mistral Nemo-12B Instruct across RunPod and Vast.ai using the patterns described in this article.
To keep our deployment experience consistent across services and clouds, we built a set of reusable GitHub Actions workflows that handle Gateway and service deployments, as well as DNS record updates. This ensures every AI project we have follows the same deployment path, reducing friction and space for human error.
#Monitoring & Troubleshooting
Beyond deployments, dstack provides essential visibility into our running workloads through its web UI. We use it daily to monitor our LLM and image-generation services spread across RunPod and Vast.ai, in addition to other monitoring tools.
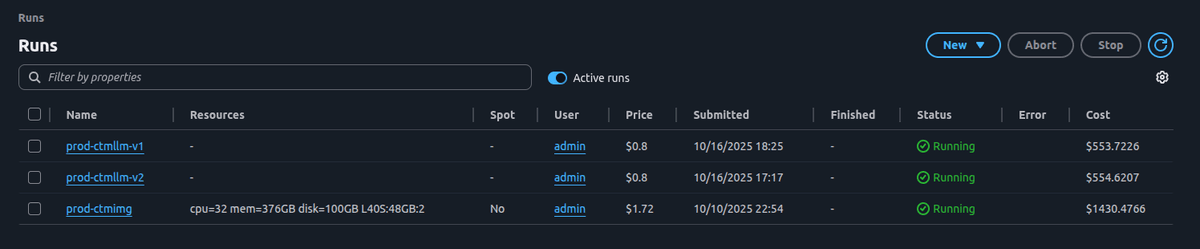
The interface shows all active runs with their resource allocations, costs, and current status across both providers.

When investigating performance issues or validating new model deployments, we drill into individual services to examine replica-level metrics—CPU and GPU utilization, memory consumption, and detailed logs from each instance.
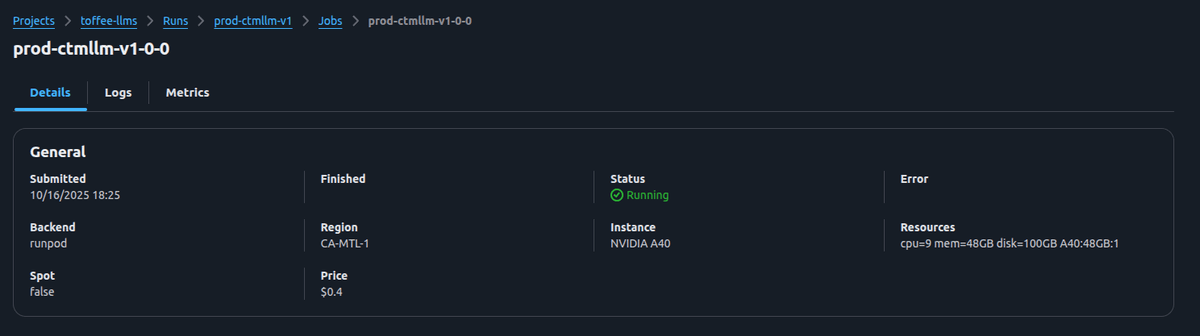
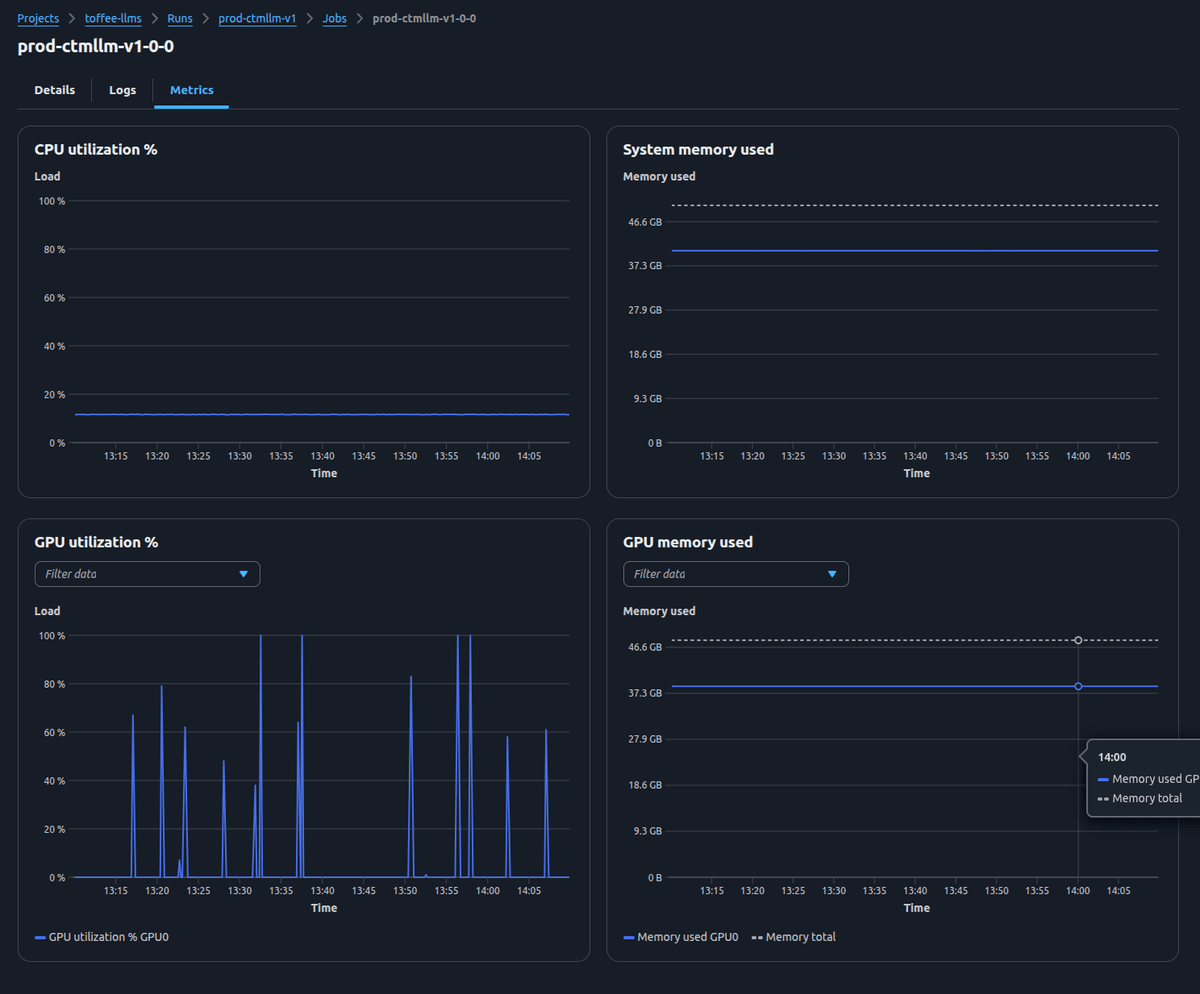
This unified view across multiple clouds has been crucial for identifying which replicas are handling load efficiently and catching provider-specific issues before they cascade.
#Before dstack: A Fragile Custom Approach
Before adopting dstack, we provisioned AI workloads using custom CLI scripts and in-house Terraform modules that wrapped RunPod's GraphQL API. While it worked, maintaining this setup became increasingly painful as we had to scale rapidly to adopt new users.
To enable private cross-service communication, we deployed Cloudflare Zero Trust Tunnels behind CF Zero Trust Applications, managing credentials on a per-service basis. Though Cloudflare Tunnels enabled basic load balancing out of the box, we couldn't achieve zero-downtime deployments or autoscaling without significant additional engineering. Building these features ourselves made no sense, besides, we needed to focus on our core product, not infrastructure plumbing.
This is when we evaluated options on the market and chose dstack. It had all the features we needed to scale, was actively maintained, had a vibrant community, and offered responsive support when we needed help.
#Trade-offs and Considerations
dstack has been transformative for our infrastructure. However, like any platform, it involves trade-offs, though many are offset by the value it provides and the supportive team behind it.
Documentation, while improving, sometimes lags behind new features. The dstack team maintains a dedicated Slack channel where they're remarkably responsive—we've received detailed answers to complex questions often within hours, and they've been genuinely receptive to feedback about documentation gaps. When we've hit edge cases around Gateway configuration or service networking, community help has been invaluable.
We can't implement complex scaling policies based on custom metrics, and this limits some optimization opportunities on our end. The dstack team is actively working to improve this in the near future. Additionally, each Gateway runs as a single EC2 instance rather than a highly available cluster. While we haven't experienced Gateway downtime, a failure would impact all services behind it until we could provision a replacement. We've mitigated this with CloudWatch alarms and automated recovery procedures, and it fits our infrastructure needs better than any alternative we've evaluated.
#The Peace of Mind dstack Brings
Our infrastructure team spends less time fighting fires and more time optimizing costs, improving reliability, and unblocking product teams. Our model and product teams focus on what matters—experimentation and user experience—rather than repeatedly solving the same operational problems.
For teams wrestling with similar challenges on GPU clouds, dstack eliminates the burden of building your own orchestration layer. It's infrastructure tooling that lets you move fast without the sprawl.
If you want to explore these patterns hands-on, check out our demo repository. It's a simplified, production-ready example that demonstrates the core concepts discussed here: multi-cloud GPU deployment, template-based configuration, and automated workflows. The repository includes comprehensive documentation and is designed to be a practical starting point for teams evaluating dstack.